










When building a bulk payout system that handles hundreds or thousands of transfers, you want to make sure transactions are processed completely, and everyone’s balances are updated appropriately. Whether it's multi-currency payroll, bulk disbursements, or mass vendor payments, getting batch payment processing right from the start saves you from costly reconciliation issues later.
If you try to handle each payment one by one, things get messy fast. You'll end up with systems that break easily and recovery processes that are way too complicated.
When implementing bulk payouts developers face various integration complexities. You would have to deal with complexities such as API rate limits when mass requests are throttled.
In this guide, you’ll learn how to handle bulk payouts using Blnk ledger. The same bulk transactions API also works for loan disbursements and scheduled repayments.
Prerequisites
Before we start, make sure you have:
- A running instance of Blnk. If you're setting up for the first time, our best practices guide walks you through how to structure your ledger correctly.
- Optionally, sign up to Blnk Cloud to manage your data as you build.
Set up your multi-currency payroll ledger
First things first, we need to set up our ledger architecture. This is how ledgers and balances are structured in our Core for easier reference.
For this article, we’ll design an internal payroll ledger for Acme Inc., a 3,000-person team with employees in 12 countries. Our ledger must have the following:
- Multi-currency: We’ll be paying out to 12 different countries with different tax laws and we may need to track them.
- Payslip generation: Every employee must own a balance to track their entire payroll history within the company.
- Internal accounting/auditability: The Acme Finance team must be able to track and reconcile money movement on the company accounts.
To implement this in our ledger:
- Create ledgers per country: This allows us to group employees from a particular country in one place, e.g., USA Ledger for all US-based employees, ITA Ledger for all Italy-based employees, and so on. Read docs.
- Create an identity for each employee: Record every employee as an entity in the ledger. This will be important for the next step. Read docs.
- Create a balance for each employee: Using the employee’s identity and their respective country of residence, create a balance for each employee. Read docs.
Fund your payroll account
Now that you’re set up, let’s work on payments.
Before we process payouts to employees, we need to first fund a company payroll balance. This sets a clear payroll budget for the period and gives Blnk a limit to work with. As a result, each payout is validated against the available payroll balance, allowing Blnk to track/manage cases where requested payouts exceed the payroll balance.
To do this, we’ll fund a balance dedicated to Acme’s payroll in our ledger. We’ll call it “@PayrollBalance.” Read docs on internal balances.
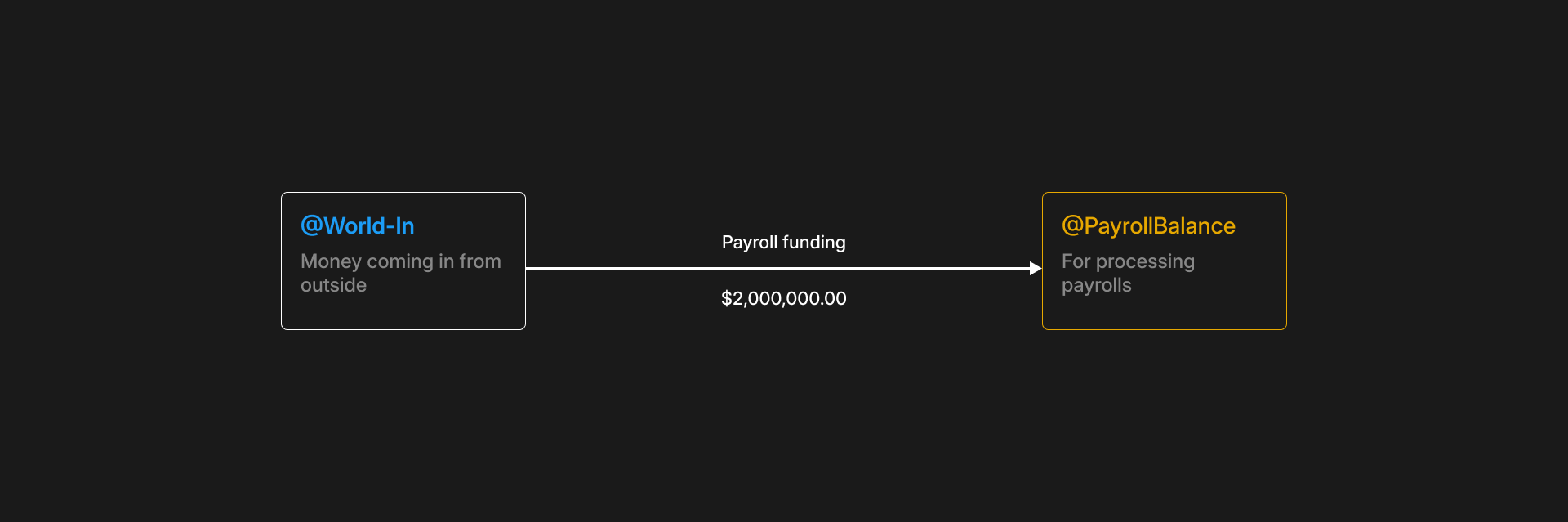
To fund the payroll account, we’ll create a transaction to represent a deposit from the business’ bank account to their payroll balance in your product:
```
--CODE language-bash--
curl -X POST http://localhost:5001/transactions \
-H "Content-Type: application/json" \
-H "X-blnk-key: YOUR_API_KEY" \
-d '{
"amount": 2000000,
"precision": 100,
"reference": "business_funding_2025-01-15",
"currency": "USD",
"source": "@BankDeposits",
"destination": "@PayrollBalance",
"description": "Payroll funding for January 2025",
"allow_overdraft": true
}'
```
In our example, we deposited $2,000,000.00 into Acme’s payroll balance. We used @BankDeposits as our source to ensure double-entry.
Our @BankDeposits balance here has been automatically created by Blnk in our general ledger because it was specified with “@”
Process bulk payroll payments
Now, it’s that time of the month! Let’s payout 3,000 employees.
We can do this in two ways:
- Synchronous processing: Process everything in one go, and return a success/failed response.
- Async processing: Process all transactions in the background, and notify via webhooks/events.
Synchronous bulk payment processing
With this, your batch payment would be processed in a single request. For Acme, we can process bulk payouts in batches of 100, i.e. a total of 30 requests to complete processing.
Now, we’ll create the bulk transaction request. You can create an array of transactions—one for each employee—and send them all in a single request.
First, let's prepare the transaction for a few employees:
```
--CODE language-bash--
curl -X POST http://localhost:5001/transactions/bulk \
-H "Content-Type: application/json" \
-H "X-blnk-key: YOUR_API_KEY" \
-d '{
"run_async": false,
"transactions": [
{
"amount": 8752,
"precision": 100,
"reference": "PAYROLL_EMP150_2025-01-15",
"description": "Salary payment for Stacy Jones - 2025-01-15",
"currency": "USD",
"source": "@BusinessAccount",
"destination": "bln_c37fa6ca-b430-48f1-9095-1ebc514589d6",
"allow_overdraft": false,
"meta_data": {
"employee_id": "EMP150",
"employee_name": "Stacy Jones",
"payroll_period": "2025-01-15",
"payment_type": "salary"
}
},
{
"amount": 7243,
"precision": 100,
"reference": "PAYROLL_EMP149_2025-01-15",
"description": "Salary payment for Gene Wells - 2025-01-15",
"currency": "USD",
"source": "@BusinessAccount",
"destination": "bln_6c99439c-99e1-4f9b-923b-493693f38dff",
"allow_overdraft": false,
"meta_data": {
"employee_id": "EMP149",
"employee_name": "Gene Wells",
"payroll_period": "2025-01-15",
"payment_type": "salary"
}
}
// Add more transactions here
]
}'
```
run_async: false tells Blnk that the transactions should be processed synchronously. For larger batches, the request may take longer to complete.
Once completed, you should see the following response:
```
--CODE language-json--
{
"batch_id": "bulk_32472ce2-0ba2-46c1-b796-aafc6cd31811",
"status": "applied",
"transaction_count": 2
}
```
Store or use the batch_id to reference this batch in other operations.
Async bulk payment processing
With async processing, run_async: true, Blnk accepts the request and returns a response telling you that it is being processed in the background.
With this, we can pass all 3,000 transactions in our payload without worrying about server timeouts:
```
--CODE language-bash--
curl -X POST <http://localhost:5001/transactions/bulk> \\
-H "Content-Type: application/json" \\
-H "X-blnk-key: YOUR_API_KEY" \\
-d '{
"run_async": true,
"transactions": [
{
"amount": 5000,
"precision": 100,
"reference": "PAYROLL_EMP001_2025-01-15",
"description": "Salary payment for Employee 1 - 2025-01-15",
"currency": "USD",
"source": "@BusinessAccount",
"destination": "bln_employee_1_balance_id",
"allow_overdraft": false,
"meta_data": {
"employee_id": "EMP001",
"employee_name": "Employee 1",
"payroll_period": "2025-01-15"
}
}
// ... add 2,999 more transactions here
]
}'
```
Expected response:
```
--CODE language-json--
{
"batch_id": "bulk_204fa664-7171-4c38-9533-cc1086063376",
"message": "Bulk transaction processing started",
"status": "processing"
}
```
Since it is async, a batch_id is returned immediately and the payments continues in the background.
To know when the transactions have been processed, set up webhooks to listen for transaction.applied events and use them to trigger bank payouts via your payment provider.
This way, you can ensure that the transaction is verified first in your ledger before money leaves your system.
.png)
Retrieve all transactions in a payroll batch
To retrieve all transactions that belong to the same batch, use the Search API and query by a shared key such as a batch_id.
Async bulk transactions
Blnk automatically assigns a batch identifier and stores it in transaction metadata under QUEUED_PARENT_TRANSACTION. You can use this value to retrieve all transactions in the single batch.
```
--CODE language-bash--
curl -X POST <http://localhost:5001/search/transactions> \\
-H "Content-Type: application/json" \\
-H "X-blnk-key: YOUR_API_KEY" \\
-d '{
"q": "bulk_c62f200b-905f-4983-a349-cadd279234aa",
"query_by": "meta_data.QUEUED_PARENT_TRANSACTION"
}'
```
This is the recommended approach for queued or asynchronous processing, since grouping is handled automatically.
Synchronous transactions
For synchronous processing where multiple transactions are created without a single batch_id, include your own shared identifier in the transaction metadata.
For example, you might add a value like tag: payroll-jan-2026 to each transaction.
You can then retrieve all related transactions by querying that metadata field:
```
--CODE language-bash--
curl -X POST <http://localhost:5001/search/transactions> \\
-H "Content-Type: application/json" \\
-H "X-blnk-key: YOUR_API_KEY" \\
-d '{
"q": "payroll-jan-2026",
"query_by": "meta_data.tag"
}'
```
This approach gives you full control over grouping when transactions are created synchronously or across different workflows.
Alternatively, you can filter on Cloud and save to view for easy reference and operations. You can also generate employee payslips and payroll statements directly from your ledger data.
.png)
You now have a working bulk payroll system. Get started with Blnk to try it out yourself. If you have any questions about this guide, reach out on Discord or send us a message.
